결정 트리와 부스팅
이번 시간에는 결정 트리와 부스팅에 대해 알아보겠습니다.
결정 트리와 부스팅
목차
1. 결정트리
결정트리는 데이터를 반복적으로 분할하여 결과를 예측하거나 분류하는 트리 형태의 모델입니다.

위 그림은 Iris 데이터에 결정 트리를 적용한 예시이며, 결정 트리에서 자주 사용되는 용어는 아래 표에 작성했습니다.
| 용어 | 설명 |
| 뿌리 노드(root node) | 전체 의사결정나무가 시작되는 마디로, 전체 자료를 포함 |
| 부모 노드(parent node) | 주어진 마디의 상위에 있으며 자녀 노드를 가지고 있음 |
| 자녀 노드(child node) | 부모 마디로부터 분리되어 나간 2개 이상의 마디. 자녀 노드는 또 다른 부모 노드가 될 수 있음 |
| 리프 노드(leaf node) | 더 이상 분할되지 않는 노드. 예측 값을 가지며, 클래스 혹은 회귀값으로 반환 |
| 깊이(depth) | 뿌리 노드부터 가장 먼 리프 노드까지의 경로에 있는 노드들의 수 |
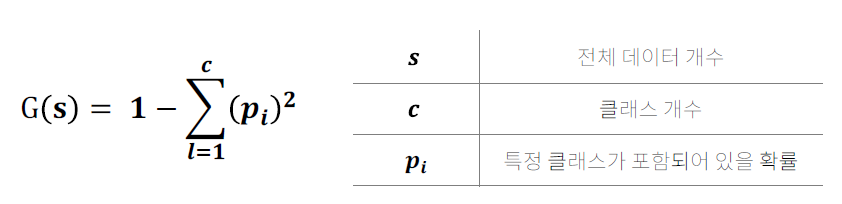
결정 트리는 기준에 맞춰 데이터를 분할하기 위해 지니 계수와 엔트로피를 사용합니다. 지니 계수는 한 그룹 안에서 데이터가 얼마나 섞여 있는지를 나타내는 기준으로 아래 수식으로 정의할 수 있습니다. 값이 클수록 불순도(다른 클래스의 데이터가 들어가 있는 정도)가 높아지고 순수도는 낮아집니다. 클래스가 2개일 때 최대 지니 계수는 0.5입니다.
엔트로피도 지니 계수처럼 한 그룹 안에서 데이터가 얼마나 섞여 있는지를 나타내는 기준입니다. 다만, 계산 식에서 로그를 적용해 지니 계수보다 작은 차이를 더 민감하게 반영할 수 있어 데이터 불균형이 심할 때 사용하기 적합합니다. 클래스가 2개일 때 최대 엔트로피 지수는 1.0입니다.

결정트리의 장단점은 아래 표와 같습니다.
| 구분 | 설명 |
| 장점 | - 해석의 용이성: 나무 구조(if-then)에 의해 표현되어 모델을 쉽게 이해할 수 있음 - 주요 변수 파악: 종속 변수를 잘 설명할 수 있는 독립변수 파악 가능 및 분리 기준 제시 - 비모수적 모형: 데이터의 통계적 가정이 필요 없음 - 유연성과 정확도: 수치형 및 범주형 데이터 모두 사용 가능하며, 분류 정확도가 높음 |
| 단점 | - 많은 데이터, 많은 시간: 좋은 모형을 생성하는데 비교적 많은 데이터와 시간이 소요됨 - 비연속성: 분리 시 연속형 변수를 구간화 처리, 분리 경계점 근처에서 오류 발생 가능성 있음 - 선형 구조에 적합하지 않음 |
2. 부스팅
부스팅은 앙상블의 한 종류로, depth가 얕은 약학습기(weak learner)들을 순차적으로 결합해 강학습기(strong learner)를 만드는 방법입니다.
약학습기들을 여러 개 만들고 순차적으로 약학습기들을 결합하면서 이전 학습기에서 틀린 부분(개별 데이터 or 손실함수)에 대한 가중치를 크게 만들면서 학습을 유도합니다. 부스팅 기법은 적절히 설정된다면 높은 성능과 더불어 과적합을 방지할 수 있다는 장점이 있습니다.
부스팅의 종류는 매우 다양한데 여기서는 AdaBoost, GBM, XGBoost, LightGBM에 대해 알아보겠습니다.
1) AdaBoost
AdaBoost(Adaptive Boost)는 부스팅 기법의 원조로 약학습기에서 틀렸던 개별 데이터에 가중치를 부여하는 방식으로 부스팅을 진행합니다.
최종 결정을 내릴 때 성능이 좋은 학습기들의 비중을 높이고 그렇지 않은 학습기들의 비중을 낮게 반영해 성능이 가장 높은 예측값을 반환합니다.
AdaBoost의 장단점
| 구분 | 설명 |
| 장점 | - 성능 향상: 약학습기를 결합해 강학습기를 생성 - 간단한 알고리즘: 구현이 쉽고 약학습기를 기반으로 간단하게 작동 |
| 단점 | - 노이즈에 민감: 이상치나 노이즈에 지나치게 높은 가중치를 부여할 수 있음 - 클래스 불균형에 민감: 소수 클래스에 과도한 가중치가 부여되어 과적합이 발생할 수 있음 - 데이터 크기 제한: 대규모 데이터셋에서는 학습 속도가 느림 |
2) Gradient Boosting Machine(GBM)
GBM은 손실함수의 경사하강법을 사용해 약학습기를 순차적으로 학습합니다.
GBM은 유연성이 높기 때문에 다양한 손실함수(회귀, 분류 등)을 적용할 수 있습니다.
GBM의 장단점
| 구분 | 설명 |
| 장점 | 성능이 우수하며, 다양한 유형의 데이터에 적합 |
| 단점 | 계산 비용이 높고, 학습 시간이 오래 걸릴 수 있음 하이퍼파라미터 튜닝이 까다로움 |
3) XGBoost
Extreme Gradient Boosting은 GBM의 개선된 버전으로 병렬처리, 가중치 규제 등이 추가되었습니다.
XGB의 장점
| 구분 | 설명 |
| 장점 | 빠른 속도와 높은 예측 성능 결측치 자동 처리 및 다양한 커스터마이징 옵션 |
| 단점 | 복잡한 구조로 인해 학습 곡선이 높을 수 있음 |
4) LightGBM
XGB의 경량화된 버전으로 대용량의 데이터셋과 높은 차원의 데이터에 적합합니다.리프 중심 방식으로 트리를 생성해 효율성을 높였습니다.
LGB의 장단점
| 구분 | 설명 |
| 장점 | 매우 빠른 학습 속도와 낮은 메모리 사용량 대규모 데이터셋에 적합 |
| 단점 | 작은 데이터셋에서는 성능이 떨어질 수 있음 |
이번 시간에는 결정 트리와 부스팅에 대해 알아봤습니다.